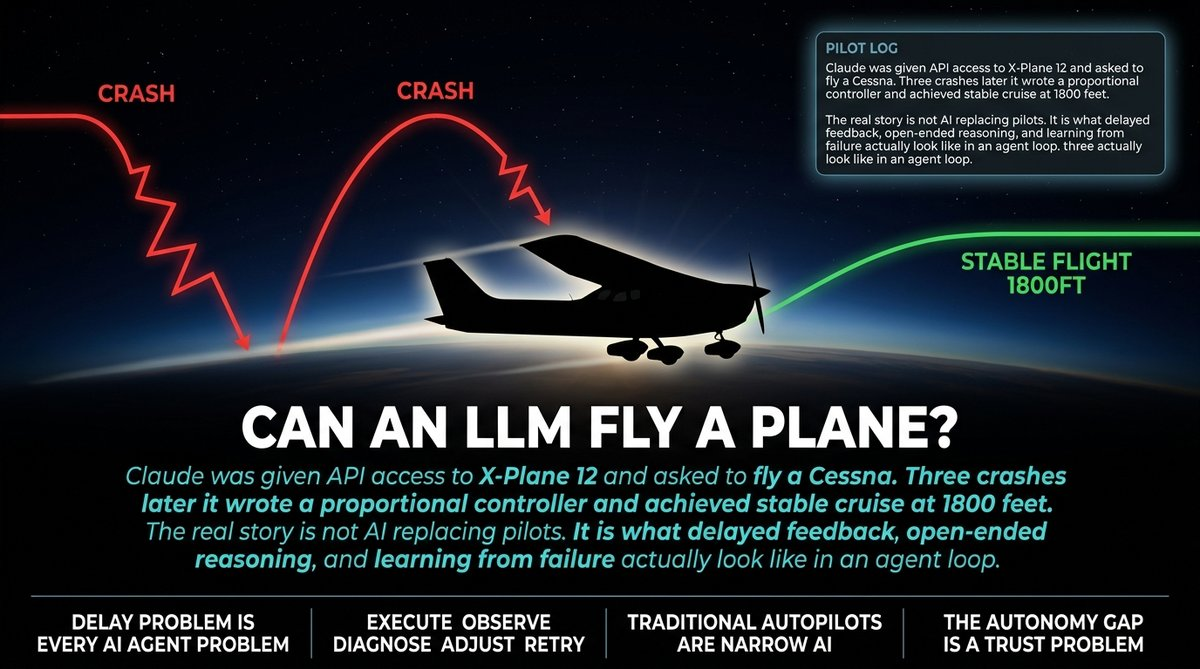
A developer put Claude in an X-Plane flight simulator and asked it to fly a Cessna from Hainan to a nearby airport. The goal was not to replace pilots. It was to test whether an LLM can reason about real-time delayed feedback, build its own tools, and plan ahead before taking action.
The result: three crashes, a complete rewrite of the flight controller from scratch, and stable cruise flight at 1800 feet on the third attempt.
I run a small agency that builds AI automation for business workflows. This is not an aviation story to me. It is a story about every client project I have shipped in the past year.
Here is what happened. Claude kept a pilot’s log throughout the flight, reasoning through its own decisions in real time. When it crashed, it diagnosed the failure, rewrote the control logic, and tried again. On the third attempt it achieved stable flight. That loop — execute, observe, diagnose, adjust, retry — is exactly what I tell clients they are buying when they pay for AI agent development.
The problem is that nobody talks about what happens in month six of a production deployment, when the agent has been running unattended and the feedback loop stretches from milliseconds to hours.
Here is the thing that got me. The main technical challenge was not intelligence. It was delay. By the time Claude saw what happened after issuing a command, the plane was in a different state. It commanded a course change, but by the time the effect registered, the situation had changed. The model was flying a plane that was already somewhere else.
This is the feedback loop problem. Every AI agent in production faces it. The Cessna kept crashing because Claude issued commands faster than the physics could execute them. This is not a prompt engineering problem. It is a fundamental engineering problem that the vibe coding crowd does not want to hear about because it does not fit in a demo.
The model decided to write the takeoff automation before even thinking about how to steer or land. The developer flagged this as an interesting sequencing choice. Get airborne first, add landing logic later. That tells you something about how the model plans when it is operating in unfamiliar territory — it picks the goal that gets it moving and hopes it can figure out the rest.
My hot take: this is exactly how small agencies lose clients. The AI takes off and nobody has thought through the landing.
Modern commercial aircraft already have advanced autopilots. We still put human pilots in the cockpit. The reason is not technical. The reason is trust and edge cases. When something goes wrong that the system was not designed for, you need a human with judgment who can improvise outside the script.
Claude was operating in open-ended space it had not been trained on. That is the exact position your AI workflow lands in when a client feeds it data that does not match the training distribution, or when an upstream API changes its response format, or when the business logic that seemed clear in the pitch meeting turns out to be ambiguous in practice.
One commenter in the HN thread pointed out that traditional autopilots are designed for specific known scenarios. They do not have to figure out what to do when something unexpected happens. They just execute the script. Claude was doing something different — it was reasoning its way through problems it had never seen.
That is the autonomy gap. And it is the reason I am still skeptical of fully autonomous AI deployments for anything a client actually cares about.
The final stable flight controller was a proportional design: altitude error to target pitch to a P-controller on elevator. No integral term in the inner loop. The developer noted in the pilot’s log that the airframe is the integrator. That is genuinely thoughtful engineering from a system that started by crashing into a runway.
The lesson I am taking from this is not about aviation. It is about the gap between demos and production.
If you are a small business or solo operator thinking about AI agents to automate your workflows, here is what this story actually means. The model is capable. The engineering required to make it work reliably is real and ongoing. The crashes were not the failure — the failure was not having a recovery plan when the crashes happened.
You do not need to understand flight physics. You need to understand that every automation you deploy will crash eventually, and the question is whether you have built the diagnostics and retry logic to survive it without a human in the loop burning hours to debug what went wrong.
Claude flew the plane on the third try. That is the relevant data point. The first two failures were not bugs. They were the process working as designed. The question is whether your automation has enough observability and recovery architecture to iterate that fast when something goes wrong in production.
Spoiler: most do not.
Sources:
– Original Experiment
– Hacker News Discussion