Key Takeaways
– SubQ achieved impressive results on a benchmark at a high token count, just barely ahead of another model.
– On a different benchmark, SubQ had a notable production score, while the other model managed a significantly lower score.
– Running the benchmark at a high token count costs much less on SubQ compared to the other model at equivalent context length.
– No public API. No tech paper. No open weights. Waitlist only.
– Independent researchers: whether SubQ actually delivers subquadratic scaling “remains an empirical question that only independent evaluation can settle.”
So here’s this number: a remarkably low cost. Subquadratic, a Miami startup nobody knew existed six months ago, dropped that figure alongside benchmark scores that made my timeline feel slightly unhinged for about 24 hours.
Let’s actually look at what the numbers mean.
And where the holes are.
The Core Claim in Plain English
SubQ. Large token context window.
Subquadratic Sparse Attention.
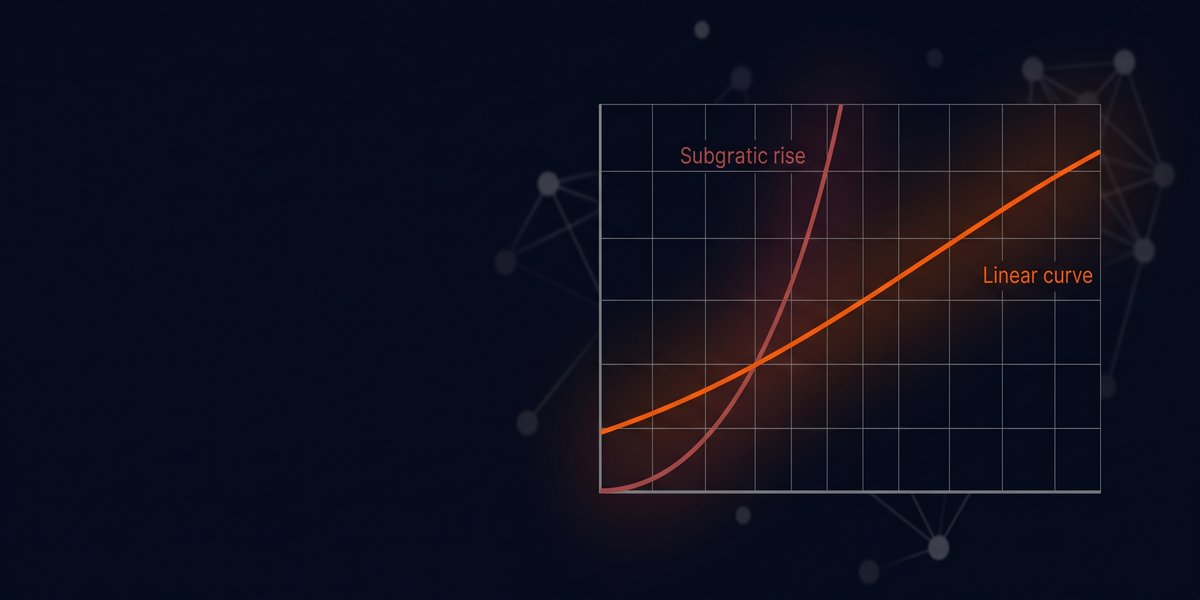
The pitch is that their attention math scales linearly instead of following the standard curve that makes long contexts financially painful.
If that holds up, it’s not an improvement.
It’s a different game entirely.
Rent vs mortgage. Same house.
Now the benchmark reality.
The results at a high token count — SubQ: impressive results. The other model: also strong results. That’s basically a tie. And that’s worth saying because the benchmark is exactly the test a long-context model should excel at.
The results on another benchmark tell a stranger story. SubQ had a notable production score. The other model had a significantly lower score. Other models also performed, but with varying results.
The rank order makes sense. But that gap between SubQ and the other model? Subquadratic also reported a strong research score. The delta between that and the production number? That’s the kind of gap that shows up in early launches and evaporates once things get production-hardened. Happened before.
Might happen here.
On a verification benchmark, SubQ scored well.
Same neighborhood as frontier models on code. Worth noting since the underlying architecture is doing something completely different.
The Math Nobody Talks About
Here’s why the low cost figure won’t leave me alone.
Standard transformer attention. Every token talks to every other token. At a smaller token count, fine. At larger token counts, costs increase significantly. At the highest token counts, the numbers get absurd. That’s why frontier providers charge premium rates for long context. That’s why most production systems just… route around it. RAG. Chunking.
Hoping the model doesn’t actually need the whole document.
SubQ says skip that entire problem.
Compute attention only on significant token relationships. Content-dependent sparse attention. They claim significant speed improvements at high token counts. At even larger token counts, they suggest a dramatic reduction in compute compared to the competition.
Either this is the biggest efficiency jump since the original transformer. Or it’s the most carefully tuned benchmark environment in recent memory.
I genuinely don’t know.
What I know: the cost for a full run on the other model is significantly higher. A much lower cost for the same test on SubQ. That number sticks in your head.
The Evaluation Problem
Let me be precise here. “Third-party verified” and “independent academic reproduction” are not the same thing.
Subquadratic paid for the benchmarks.
Better than self-reporting. Not the same as a university lab running it independently with published methodology.
A writeup flags it: the strong numbers come from a service SubQ hired. Not reproduced by external labs.
Every comment thread on HN, Reddit, YouTube. Same issue. No public weights. No open demos. No transparent benchmark suite beyond the metrics the company picked. Researchers are summarizing vendor numbers.
That’s not the same as verifying them.
VentureBeat caught the mood: whether SubQ actually delivers subquadratic scaling “remains an empirical question that only independent evaluation can settle.” That’s the right position. That’s the only reasonable stance before you build anything around it.
The API — SubQ isn’t generally available. Early access only. No public per-token pricing. Can’t independently validate cost claims without running the benchmarks yourself. And Subquadratic hasn’t published a real technical paper describing their sparse attention architecture. That’s unusual for a claim this size.
What It Would Mean If True
Here’s the thing.
If even half of this holds up under independent testing, small teams benefit the most.
The cost difference isn’t a rounding error.
It’s the difference between running full repo context analysis in your CI pipeline and calling it a “special project.” It’s the difference between persistent agent memory that spans months of conversation and a model that times out at a high token count.
I run an AI automation shop. My clients aren’t Fortune 500 procurement teams. They’re small businesses, indie developers. Automation that has to actually pencil out.
If SubQ delivers even half the cost reduction at high token counts, workflows that were fantasy at high costs become real at much lower costs.
Honest take? Right now SubQ is vaporware with unusually detailed benchmarks. The gap between announced and delivered is the actual history of AI. Grok, Gemini, every frontier model. Available today, shipping real work, pricing you can look up.
SubQ has a waitlist and a social media post.
What to do: follow that waitlist. Set a reminder for launch day. Watch what independent labs report in the first two weeks after GA. In the meantime, build with what exists.
The question gets answered eventually. By whom, and when. That’s the only open question.